KnowMT-Bench: Benchmarking Knowledge-Intensive Long-Form Question Answering in Multi-Turn Dialogues
Sep 26, 2025·, ,,,,,,,·
1 min read
,,,,,,,·
1 min read
Junhao Chen
Yu Huang
Siyuan LI
Rui Yao
Hanqian Li
Hanyu Zhang
Jungang Li
Jian Chen
Bowen Wang
Xuming Hu
 KnowMT-Bench: Multi-Turn Knowledge-Intensive QA Framework
KnowMT-Bench: Multi-Turn Knowledge-Intensive QA FrameworkAbstract
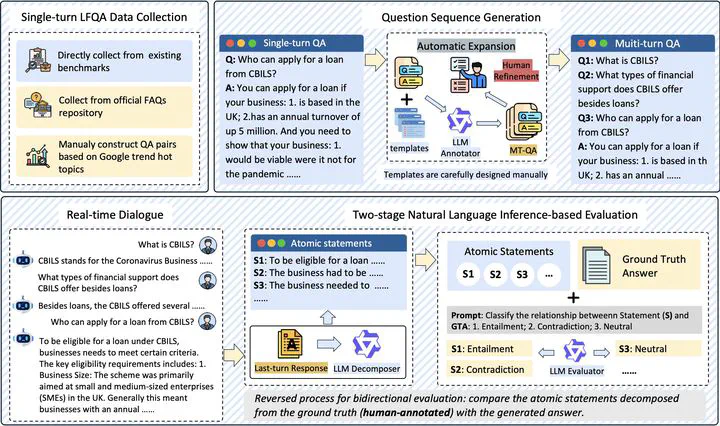
Multi-Turn Long-Form Question Answering (MT-LFQA) is a key application paradigm of Large Language Models (LLMs) in knowledge-intensive domains. However, existing benchmarks are limited to single-turn dialogue, while multi-turn dialogue benchmarks typically assess other orthogonal capabilities rather than knowledge-intensive factuality. To bridge this critical gap, we introduce KnowMT-Bench, the “first-ever” benchmark designed to systematically evaluate MT-LFQA for LLMs across knowledge-intensive fields, including medicine, finance, and law. To faithfully assess the model’s real-world performance, KnowMT-Bench employs a dynamic evaluation setting where models generate their own multi-turn dialogue histories given logically progressive question sequences. The factual capability and information delivery efficiency of the “final-turn” answer are then evaluated using a human-validated automated pipeline. Our experiments reveal that multi-turn contexts degrade performance: factual capability declines due to the contextual noise from self-generated histories, while information efficiency drops as models become more verbose with increasing dialogue length. We then investigate mitigation strategies, demonstrating that retrieval-augmented generation (RAG) can effectively alleviate and even reverse this factual degradation. These findings underscore the importance of our benchmark in evaluating and enhancing the conversational factual capabilities of LLMs in real-world knowledge-intensive applications. Code is available at https://github.com/hardenyu21/KnowMT-Bench.
Type
Publication
In arXiv preprint
Abstract
Multi-Turn Long-Form Question Answering (MT-LFQA) is a key application paradigm of Large Language Models (LLMs) in knowledge-intensive domains. However, existing benchmarks are limited to single-turn dialogue, while multi-turn dialogue benchmarks typically assess other orthogonal capabilities rather than knowledge-intensive factuality.
This paper introduces KnowMT-Bench, the first-ever benchmark designed to systematically evaluate MT-LFQA for LLMs across knowledge-intensive fields, including medicine, finance, and law.